PintOS 제작기 - 1
PintOS
서론
PintOS 중 우리는 카이스트에서 개발한 운영체제를 직접 만들어본다. 이는 주차들로 나뉘어 각각의 프로젝트를 만들게 된다.
Project 1 - 서론
Project 1에서는 Base kernel의 Source Code를 제작하게 된다. 이는 threads directory에 있다.
또한, I/O device interfacing 과정을 진행하게 되는데, 이는 devices directory에 있다.
Project 2 - 서론
Project 2 에서는 User Program Loader를 제작하게 된다. 이는 userprog directory에 있다.
lib directory에서 standard C library의 일부를 implement 하게 된다.
Project 3 - 서론
Project 3 에서는 Virtual Memory를 구현하게 된다. 이는 vm directory에 있다.
Project 4 - 서론
Project 4 에서는 basic file system을 구현하게 된다. 이는 filesys directory에 있다.
이는 사실 project 2에서 실제로 처음 사용하게 되지만, 내부를 수정하는 것은 Project 4에 와서 진행한다.
본론
Project 1
Project 1에서는 먼저 최소한의 작동하는 쓰레드 시스템을 제공한다. 우리는 이를 확장시키어 동기 문제들에 대해 더 잘 이해하게 될 것이다. 우리는 기본적으로 threads directory에서 작업을 진행하고, 또한 devices directory에서도 일부의 작업을 진행할 필요성이 있다. threads directory에서 이후 합치는 작업을 진행해야 하며, 이 아래를 진행하기 전에 Synchronization을 한번 읽어보는 것이 좋겠다.
Backgrounds
Understanding Threads
먼저, initial thread system의 코드를 읽고 이해해라. Pintos는 이미 쓰레드 생성, 쓰레드 Completion(완성, 종료), 쓰레드 사이의 Context Switching을 진행시키는 간단한 스케쥴러와 동기화의 가장 작은 요소들(세마포어, 락, 환경 변수, 최적화 배리어 등…)을 구현시켜 두었다.
코드가 처음에는 좀 어려울 수 있다. 아직 컴파일을 진행하고 베이스 시스템을 돌리지 않았다면, Introduction에서 다시 확인하여 진행하고 이곳으로 돌아오도록 해라. 소스 코드의 모든 부분을 편하게 확인할 수 있다. 필요하다면, printf() 문을 이곳저곳에 추가하고 이를 컴파일하여 돌려봄으로써 어떤 일들이 어떤 순서로 일어나는지 확인하도록 해라. 또한, 커널을 디버거에서 돌려서, 이곳저곳 흥미로운 지점들에 중단점(breakpoints)을 추가하여 코드 안쪽까지 데이터를 확인해보며 진행하여도 좋다.
쓰레드가 만들어질 때, 우리는 스케쥴될 새로운 context를 만든다. 우리는 이 상황에서 작동하는 함수를 만들어야 하며, 이는 thread_create()함수의 인자의 내용으로 전달될 것이다. 처음 쓰레드가 스케쥴되고 동작할 때, 이 함수로 시작되며 이 내용이 실행될 것이다. 함수가 반환되면, 쓰레드가 종료된다. 각 쓰레드는, 그러므로, 미니 프로그램처럼 동작하며, 이는 thread_create()가 main() 처럼 실행되며 이에게 넘겨준다.
어떠한 아무런 시간이 주어진다면, 단 하나의 쓰레드만 동작해야 하며, 나머지가 있다면 이들은 비활성화된다. 스케쥴러는 다음에 어떤 쓰레드가 동작해야 하는지를 결정한다(만약 어떠한 쓰레드도 동작할 준비가 주어진 시간에 되지 않는다면, idle()로 구현된 특별한 idle 쓰레드가 동작한다.).
동기화의 가장 작은 단위들(Synchronization primitives)(위에 설명한 세마포어나 락, 환경변수 등)은 context switch를 한 쓰레드가 다른 쓰레드가 작업할 동안 기다려야 한다면 강제로 발생시킬수 있다.
Context Switch의 동작 과정은 threads/thread.c 안에 존재하는 thread_launch() 함수에 자세히 담겨 있다(꼭 이해할 필요는 없다.). 이는 현재 동작중인 쓰레드의 상태를 저장하고, 우리가 동작시키고자 하는 쓰레드의 상태를 복원한다.
GDB 디버거를 통해, 천천히 Context Switch를 따라가보면(GDB 문서) 어떤 일이 일어나는지 알 수 있다. schedule() 함수에 breakpoint를 넣어서 시작해보고, single-step을 넘어가며 확인해봐라. 지속적으로 쓰레드의 주소와 상태를 확인해야 함을 꼭 기억하고, 각 쓰레드별로 어떤 작업들이 call stack에 있는지 확인해라. do_iret()에 있는 iret이 실행될 때, 다른 쓰레드가 돌아가기 시작한다는걸 곧 알 수 있을 것이다.
주의사항: Pintos에서, 각 쓰레드는 4 kB이하의 작은 고정된 실행 스택으로 규정되어 있다. 커널은 스택 오버플로우를 탐지하려 하지만, 이를 완벽하게 해내지는 못한다. 동적 지역변수로 거대한 데이터 구조를 선언하게 되면(예시 : int buf[1000];) 전혀 원인파악이 되지않는 커널 패닉(Kernel Panic)등의 기묘한 문제들을 여러분은 일으킬 수 있다.
이러한 스택 할당의 대안으로는 페이지 할당기와 블록 할당기 등이 존재한다(Memory Allocation 참고).
Source Files
threads 와 include/threads 의 대한 간략한 요약이다. 이의 대부분의 코드는 굳이 수정할 필요가 없으나, 이를 보면 조금이나마 과제를 수월하게 해낼 수 있을 것이다.
이것들은 여기참고합시다.
Development Suggestions
과거 많은 그룹들은 업무를 분할하였으며, 각 그룹 인원들은 자신의 분담된 업무를 데드라인 직전즈음까지 작업하였다. 이후, 그룹은 이들을 Merge하여 완성된 파일을 만들었는데, 이는 매우 좋지 않은 생각이다. 부디 이런방식으로 진행하지 않기를 바란다. 서로간의 코드를 합치다 발생한 오류를 해결하기 위해 마지막 시간들을 부디 허비하지 마라.
대신, git 등을 이용해 소스 코드 컨트롤을 미리미리 진행하여라.
다양한 버그에 마주칠 수 잇는데, 이럴 때 다시 디버깅 도구들의 appendix를 읽고 해결하여라. backtraces를 확인하며 kernel panic이나 assertion failure를 해결하기를 바란다.
Alarm Clock
devices/timer.c에 있는 timer_sleep()`을 다시 구현해
물론 이미 작동되는 구현이 되어있지만, 이는 busy wait 방식을 사용한다. busy wait은 계속 thread_yield() 함수를 통해 현재 시간을 확인하는 루프 속에 계속 존재하여, 충분한 시간이 지날때까지를 기다리는 방식이다. 이를 피할 수 있는 방식을 재구현해라.
1
void timer_sleep (int64_t ticks);
쓰레드를 부르는 작업을 시간이 최소 x timer ticks 만큼 지나기 전까지 멈춘다. 만약 시스템이 idle 상태가 아니라면, 쓰레드가 정확히 x tick 직후 깨어나는 것이 아니고, 적절한 시간 이후에 아무런 ready queue를 선택하게 된다.
timer_sleep()은 분명 real-time(실시간)으로 동작하는(예시로 커서를 1초에 한번 깜빡이는 동작) 쓰레드에는 도움이 되는 방식이다. timer_sleep()은 인자가 timer tick 의 형태로 구현되어 있으며, milliesecond나 다른 unit으로 구현되어 있지 않다. TIMER_FREQ timer tick per second가 구현이 되어있는데, 이는 devices/timer.h에서 확인 가능하며, 기본 값은 100이다. 어지간하면 이는 변환하지 않도록 해라.
timer_msleep(), timer_usleep(), 그리고 timer_nsleep()과 같은 다른 함수들은 milliseconds, microseconds, nanoseconds 등을 위해 존재한다. 하지만, 이들 역시 필요에 따라 timer_sleep()을 호출할 것이기에, 이를 수정할 필요는 없다. 추후에 이를 자주 사용하지는 않을 수 있으나, 프로젝트 4 에서 유용하게 사용될 수 있다.
Priority Scheduling(우선순위 스케쥴링)
Pintos에서 Priority Scheduling과 Priority Donation을 구현하라
ready list에 추가된 쓰레드가 현재 작동중인 쓰레드보다 더 높은 우선순위를 가지고 있을 때, 현재 작동중인 쓰레드는 즉시 프로세서를 새로운 쓰레드에 양보해야 한다. 유사하게, 쓰레드가 락, 세마포어나 환경 변수 등을 기다리고 있을 때, 가장 높은 우선 순위를 가지고 있는 대기중인 쓰레드가 가장 먼저 깨어나야 한다. 쓰레드는 우선순위가 시간의 경과에 따라 높아지거나 낮아질 수 있으나, 쓰레드의 우선순위가 낮아질 때, 자신이 가장 높은 우선순위 쓰레드가 아닌 경우 즉각적으로 CPU의 점유를 놓아야 할 것이다.
쓰레드 우선순위는 PRI_MIN(0) 부터 PRI_MAX(63) 까지 존재한다. 낮은 번호는 낮은 우선순위와 동일한 의미이며, 이로 인해 우선순위 0은 우선순위 중 가장 낮고, 우선순위 63은 우선순위 중 가장 높다. 쓰레드를 만들 때 우선순위는 thread_create() 함수의 인자로 받아진다. 만약 다른 우선순위를 결정할 이유가 없다면, PRI_DEFAULT(31)로 결정된다. PRI_ 매크로들은 threads/thread.h에 존재하며, 이는 절대 수정하지 않도록 한다.
우선순위 스케쥴링에서 발생할 수 있는 문제 중 하나는 “Priority Inversion(우선순위 반전)”이다. 상, 중, 하의 우선순위를 가지고 있는 세 개의 쓰레드 H, M, L을 가정하자. 만약, H가 L을 기다려야 하고(예시로, L이 락을 가지고 있는 경우), M이 이미 ready list에 올라가 있다면, H는 낮은 우선순위를 지니고 있는 L이 CPU를 점유하고 쓰레드를 완료하여 락을 반환해야 하는데, 이를 진행하지 못하므로 영원히 CPU를 가질 수 없다.
조금 더 상세한 설명
위 상황을 잘 보면, 현재 우선순위가 가장 높은 H가 CPU를 점유하고 있는데, 역으로 L이 먼저 종료되어야지만 H를 진행할 수 있다. 그렇지만, ready list에도 이미 M이 존재하고, L을 ready list에 추가해도 M보다 우선순위가 밀리므로 영원히 모두 실행될 수 없는 상황이 유지된다.
그렇기에, 이를 해결하기 위해서는 H가 “기부”를 진행하여, L이 락을 유지하는 동안 자신의 우선순위를 L에게 전달하고, L이 락을 놓게 되면(그리고 H가 락을 얻게 되면) 다시 자신이 기부한 자신의 우선순위를 되찾아 오는 방식으로 해결할 수 있다.
위에서 설명한 Priority Donation(우선순위 기부)를 구현하라. 이를 위해서는 우선순위 기부가 필요한 각기 다른 상황들에 대한 대처가 필요할 것이다. 하나의 쓰레드에 여러 개의 기부가 이루어질 수 있으므로 반드시 복수개의 기부를 감당할 수 있도록 진행하여야 한다. 예시로, H가 M이 가지고 있는 락을 기다리고 있고, 또한 M이 L이 가지고 있는 락을 기다리고 있다면, H는 M과 L 모두에 H의 우선순위가 기부되어야 할 것이다. 만약 필요하다면, level 8과 같은 적당한 우선순위 기부의 한계 깊이를 지정해야 한다.
또한 락을 위한 우선순위 기부 역시 구현되어야 한다. 다른 Pintos의 동기 구조체를 위한 우선순위는 굳이 기부할 필요는 없지만, 모든 상황에 대응되는 우선순위 스케쥴링은 구현해야 한다.
마지막으로, 쓰레드가 자신의 우선순위를 확인하고 수정할 수 있는 다음 함수들을 구현해라. 이들의 원형은 threads/thread.c에 구현되어 있다.
1
2
void thread_set_priority(int new_priority);
// 현재 쓰레드의 우선순위를 new_priority로 수정한다. 현재 쓰레드가 이로 인해 최우선 순위가 아니라면, CPU를 놓아준다.
1
2
int thread_get_priority(void);
// 현재 쓰레드의 우선순위를 반환한다. 우선순위 기부가 있다면, 더 높은 우선순위(기부받은 우선순위)를 반환한다.
다른 interface 등을 통해 한 쓰레드가 다른 쓰레드를 직접 우선순위를 수정하게 할 필요는 없다.
우선순위 스케쥴러는 다른 프로젝트들에 사용되지 않는다.
Advanced Scheduler
4.4 BSD Scheduler와 유사한 multilevel feedback 큐 스케쥴러를 현재 시스템에서 진행중인 작업들에 대한 평균 response time을 감소시키기 위해 구현해라
우선순위 스케쥴러와 마찬가지로, advanced scheduler는 우선순위를 기반으로 쓰레드를 선택하고 작동한다. 하지만, Advanced scheduler는 우선순위 기부가 일어나지 않는다. 그러므로, 우리는 우선순위 스케쥴러를 먼저 작동시키고, 이에서 우선순위 기부를 제거한 다음 advanced scheduler를 구현하는 것을 추천한다.
우리는 Pintos startup time에 어떠한 스케쥴링 알고리즘 정책을 사용할 것인지를 선택할 수 있도록 하는 코드를 작성하여야 한다. default(기본)로, 우선순위 스케쥴러가 작동하여야 지만, 또한 4.4BSD 스케쥴러를 -mlfqs 커널 옵션을 통해 선택할 수 있어야 한다. 이 옵션을 사용하면 옵션들이 main()에 존재하는 parse_options()에서 파싱될 때, threads/thread.h에 존재하는 thread_mlfqs를 true로 바꾼다.
4.4BSD 스케쥴러가 활성화되면, 쓰레드들은 더이상 직접 자신의 우선순위를 컨트롤하지 않는다. thread_create()에 전달되던 우선순위 인자들은 무시될 것이며, thread_set_priority()나 thread_get_priority()로 향하는 요청들은 스케쥴러에서 결정된 쓰레드의 현재 우선순위만 반환하게 될 것이다.
Advanced Scheduler는 추후 프로젝트에서 사용하지 않는다.
4.4BSD Scheduler
일반적 사용을 위한 스케쥴러의 목표는 쓰레드들의 밸런스를 서로 다른 스케쥴링의 필요성에 맞추는 것이다. 많은 I/O를 필요로 하는 쓰레드는 지속적으로 input 및 output devices 들을 계속 바쁘게 하기 위해 빠른 response time을 필요로 하지만, CPU는 비교적 짧은 시간동안만을 필요로 한다. 반대의 경우로, 연산을 필요로 하는 쓰레드의 경우, 상대적으로 긴 시간의 CPU를 필요로 하지만, fast response time은 전혀 필요하지 않다. 이 둘 사이에 놓인 또 다른 쓰레드들은, I/O 에 의존적인 연산 시간을 가지고 있어, 그 사이의 시간들을 또 필요로 할 수도 있다. 훌륭하게 설계된 스케쥴러의 경우, 이러한 다수의 조건들을 동시에 쓰레드들에 제공할 수 있다.
프로젝트 1을 위해서, 우리는 이 appendix에 설명된 스케쥴러를 구현하여야 한다. 우리의 스케쥴러는 [McKusik]에 설명되어 있는 것과 유사하며, 이것은 하나의 multilevel feedback 큐 스케쥴러의 예시이다. 이 형태의 스케쥴러는 다수의 ready-to-run 쓰레드들이 들어있는 큐를 유지하며, 각 큐는 각기 다른 우선순위를 가지고 있는 쓰레드들을 가지고 있다. 아무 때나, 스케쥴러는 가장 높은 우선순위를 가지고 있는 비어있지 않은 큐로부터 쓰레드를 선택한다. 만약 가장 높은 우선순위 큐가 여러개의 쓰레드를 가지고 있는 경우, 이들을 “Round Robin” 방식으로 실행시킨다.
스케쥴러의 Multiple facets는 데이터가 특정 수의 timer tick이 지난 후, 업데이트 되기를 필요로 한다. 모든 경우, 이러한 업데이트들은 일반 커널 쓰레드가 작동 기회를 얻기 전에 일어나야만 하며, 이를 통해 커널 쓰레드가 timer_ticks()은 새로이 증가한 값을 받으나, 예전 스케쥴러의 데이터 값을 받는 상황이 없게 한다.
4.4BSD 스케쥴러는 우선순위 기부를 필요로 하지 않음을 다시 강조한다.
Niceness
쓰레드 우선순위는 스케쥴러로부터 아래에 제시된 공식을 기반으로 유동적으로 결정된다. 하지만, 각 쓰레드는 nice value라고 하는 정수를 가지고 있으며, 이는 얼마나 해당 쓰레드가 다른 쓰레드들에게 “nice” 한지를 나타낸다. 만약 nice가 0이면 이는 쓰레드 우선순위에 영향을 끼치지 않는다. nice가 양수인 경우(max는 20), 쓰레드의 우선순위를 감소시키고, 받을 수 있던 CPU 시간을 조금 감소시키게 한다. 반대로 음수인 경우(min은 -20), 다른 쓰레드들로부터 CPU 시간을 뺏어온다.
시작 쓰레드는 nice값이 0으로 시작된다. 다른 쓰레드들 중 nice value가 있는 경우, 이는 자신의 부모 쓰레드로부터 받아온다. 우리는 아래에 설명된 함수들을 구현해야 하며, 이들은 테스트 프로그램을 위해서 사용된다. 이들의 원형은 threads/thread.c에 존재한다.
1
2
int thread_get_nice(void);
// 현재 쓰레드의 nice value를 반환한다.
1
2
int thread_set_nice(int nice);
// 현재 쓰레드의 nice value를 새로운 nice value로 수정하고, 다시 쓰레드의 우선순위를 새로 결정된 nice value를 기반으로 계산한다(바로 아래의 Calculating Priority를 참고할 것). 만약 현재 작동중인 쓰레드가 가장 높은 우선순위가 아니라면, CPU의 점유를 포기한다.
Calculating Priority
우리의 스케쥴러는 64개의 우선순위가 있으므로 64개의 ready 큐가 있어야 할것이며, 이들은 0(PRI_MIN) 부터 63(PRI_MAX)까지 번호가 메겨질 것이다. 작은 숫자들은 낮은 우선순위와 연결될 것이고ㅡ 그로 인해 우선순위 0이 가장 낮은 우선순위일 것이며, 우선순위 63이 가장 높은 우선순위를 가지고 있을 것이다. 쓰레드 우선순위는 쓰레드 생성시에 계산되며, 또한 모든 쓰레드에 대해 매 4회의 clock tick마다 재계산될 것이다. 어느 경우에서든, 아래의 계산식에 의해 결정된다.
$priority = PRIMAX - (recentCpu / 4) - (nice * 2)$
recent_cpu는 쓰레드가 최근에 사용한 cpu의 시간을 의미하고(이는 하단의 calculating recent_cpu 를 참고) nice 는 쓰레드의 nice value를 의미한다. 결과는 내림을 통해 가장 가까운 정수로 바꿔야 한다. recent_cpu와 nice에 곱해지는 $1/4$ 와 $2$ 는 최적화된 값으로 알고 있지만, 그보다 더 깊은 의미는 가지지 않는다. 계산된 우선순위는 반드시 가능 범위인 PRI_MIN과 PRI_MAX 사이에 존재하여야 하므로 조정되어야 한다.
이 공식은 최근 CPU time을 받았던 쓰레드가 다음에 스케쥴러가 작동할 때 CPU에게 재할당되지 않도록 하기 위해 낮은 우선순위를 부여한다. 이는 기아 현상을 감소시키는 매우 중요한 방법이다. CPU 시간을 최근에 아예 받지 못한 쓰레드가 recent_cpu 값으로 0을 가지고 있게 되므로, 높은 nice value를 부여하여, 쓰레드가 반드시 CPU 시간을 곧 받게 하는 방식으로 작동한다.
Calculating recent_cpu
우리는 recent cput를 계산하여 각 프로세스가 가장 최근에 얼만큼의 CPU time을 할당받았는지를 계산하고자 한다. 더 정제된 계산을 위하여, 가장 최근의 CPU time은 덜 최근의 CPU time보다 더 무겁게 측정되어야 한다. 하나의 접근방법은 n개의 요소가 포함된 array를 사용하여 최근 n 초간 각각의 CPU 할당 time을 계산하는 것이다. 허나, 이러한 접근방법은 쓰레드마다 새로운 recent cpu를 계산할 때 O(n)의 공간을 필요로 하며 계산마다 O(n)의 시간을 필요로 한다.
그러므로 우리는 대신, 기하급수적으로 가중치가 계산된 이동하는 평균을 구한다. 이의 대한 수식은 다음과 같다.
$x(0) = f(0),$ $x(t) = ax(t-1) + (1-a)f(t),$ $a = k/(k+1)$
여기에서 $x(t)$ 는 t>=0동안 움직이는 평균이고, $f(t)$ 는 평균이 되는 함수이며, k > 0 이 부패의 속도를 결정한다. 우리는 이를 다음과 같이 반복적으로 시행할 수 있다.
$x(1) = f(1),$ $x(2) = af(1) + f(2),$ $…$ $x(5) = a^4 * f(1) + a^3 * f(2) + a^2 * f(3) + a * f(4) + f(5)$
$f(t)$ 의 값은 time $t$ 에서 1을 가지고, 이는 time $t+1$ 에 $a$ 의 무게이며, time $t+2$ 일때는 $a^2$ 를 가진다. 이는 계속 반복된다. 우리는 $x(t)$ 를 가지고 $k$ 와 다음과 같은 연관성을 확인할 수 있다. $f(t)$ 는 time이 $t + k$ 가 되면 $1/e$ 의 값을 가지고, time $t + 2k$ 에는 $1/(e^2)$ 의 값을 가진다는 것을 확인할 수 있다. 반대의 방향으로 보자면, $f(t)$ 는 time $t + log_a(w)$ 가 되면 $w$ 만큼의 무게로 감소한다.
recent_cpu 의 시작 값은 첫 쓰레드의 경우 0으로 초기화되거나, 다른 새 쓰레드들은 부모의 recent_cpu 의 값이 된다. 매 타이머의 인터럽트가 발생할 때, recent_cpu 는 작동중인 쓰레드에서만 1만큼 증분된다. 다만 이는 idle thread가 작동하지 않을 때에만이다. 추가적으로, 1초마다 한번씩 모든 쓰레드(작동중인 것, ready 상태인 것, blocked 상태인 것 모두)에 대해 recent_cpu 의 값은 다음 수식에 의해 재계산된다.
$recentCpu = (2 * loadAvg)/(2 * loadAvg + 1) * recentCpu + nice$
load_avg 는 작동 준비가 된 쓰레드들의 수의 움직이는 평균이다(이는 아래에 좀 더 자세히 나와있다). 만약 load_avg 가 1이라면, 이는 싱글 쓰레드가 (일반적으로) CPU를 경쟁하며, 이로 인해 recent_cpu 의 무게는 $log_(2/3) .1 ≈ 6$ $.1$ 로 부패(감소) 한다. 만약 load_avg 가 2라면, .1 로 부패되는 시간은 log_(3/4) .1 ≈ 8 초로 변경된다. 이 효과는 즉 recent_cpu 는 쓰레드가 “최근에” 받은 CPU time을 계산하는 것이며, 동시에 부패의 속도도 CPU를 위해 경쟁하는 수에 반비례한다. (다시 말해, CPU를 위해 경쟁하는 쓰레드의 수가 많다면 그만큼 부패의 속도는 감소한다. 또한 이러한 부패 속도를 우리는 감쇠 속도라고 한다.)
몇가지 테스트를 위한 가정은 recent_cpu 의 대한 재계산이 정확히 system tick counter가 특정 초들에 도달했을때 이루어져야 한다는 것이다. 다시 말해, timer_ticks () % TIMER_FREQ == 0 일때 이며, 그 외의 시간에는 이것이 계산되면 안된다.
recent_cpu 의 값은 음수의 nice value를 가지고 있는 쓰레드들의 경우 음수의 값일 수 있다. recent_cpu 의 값을 그러므로 음수일 경우 0으로 조절하지 않도록 해라.
우리는 이 공식들의 계산의 순서에 대해 생각할 필요가 있을 수 있다. 우리는 recent_cpu의 coefficient를 먼저 계산하고, 그 뒤에 곱하는 것을 추천한다. 특정 학생들이 이미 load_avg 를 recent_cpu로 직접 곱하는 것이 overflow를 발생시킨다고 보고하였다.
우리는 반드시 thread_get_recent_cpu()를 구현해야 하며, 이의 원본은 threads/thread.c에 존재한다.
1
2
int thread_get_recent_cpu (void);
// 현재 쓰레드의 recent_cpu value에 100을 곱한 값을 반환하며, 이의 가장 가까운 정수로 변환하여 반환한다.
Calculating load_avg
마지막으로, load_avg 를 계산하는 방법에 대해서이다. 이는 종종 system load average로 알려져 있으며, 지난 1분간 작동 가능한 준비가 된 쓰레드의 평균 숫자를 의미한다. recent_cpu와 유사하게, 이 역시 기하급수적인 무게를 가지는 움직이는 평균이다. 하지만 priority나 recent_cpu와는 다르게, load_avg는 시스템 전체에 작용하며, 특정 쓰레드 하나에 작용되지 않는다. 시스템이 부팅될 때, 이는 0으로 초기화된다. 이에 따라 1초마다 load_avg는 다음 공식에 의해 수정된다.
$loadAvg = (59/60) * loadAvg + (1/60) * readyThreads$
준비된 쓰레드들의 숫자(readyThreads 혹은 ready_threads) running이거나 ready state를 가지고 있는 쓰레드의 수이며, 이때 idle thread의 수는 세지 않는다.
몇가지 테스트들에서 가정한 것 때문에, load_avg는 반드시 정확한 system tick counter가 특정 초들에 도착했을 때 수정되어야 한다. 이는 timer_ticks () % TIMER_FREQ == 0 일때이며, 정확이 이 때 수정되어야 한다. 우리는 thread_get_load_avg() 를 구현해야 하며, 이는 역시 threads/thread.c 에 존재한다.
1
2
int thread_get_load_avg (void);
// 현재 system load average에 100을 곱한 값을 반환하며, 이의 가장 가까운 정수로 변환하여 반환한다.
Summary
기나긴 얘기들이 오고갔지만, 간단하게 위의 여러 조건들을 이용하여 Advanced Scheduler를 구현하기 위해 공식들을 정리한다. 이것들은 스케쥴러가 필요로 하는 모든 것이 아니라는 것을 명심해라.
모든 쓰레드는 각각 -20에서 20 사이에 있는 nice value를 가지고 있으며, 스스로 이를 통제한다. 각 쓰레드는 또한 0(PRI_MIN)부터 63(PRI_MAX) 사이에 있는 priority를 가지고 있으며, 이는 매 4회의 tick이 진행될 때마다 재계산된다. $priority = PRIMAX - (recent_cpu / 4) - (nice * 2)$
recent_cpu 는 쓰레드가 최근에 부여받은 CPU time을 계산한다. 매 time tick마다, 작동하고 있는 쓰레드(running thread)의 recent_cpu는 1만큼 증분된다. 1초마다, 모든 쓰레드의 recent_cpu는 다음과 같이 재계산된다.
$recentCPU = (2loadAvg) / (2loadAvg + 1) * recentCPU + nice$
load_avg는 지난 1분간 ready to run 한 쓰레드들의 평균 수를 나타낸다. 이는 부팅될 때 0으로 초기화되며, 매 초마다 다음 공식에 의해 재계산된다.
$loadAvg = (59/60) * loadAvg + (1/60) * readyThreads$
준비된 쓰레드들의 숫자(readyThreads 혹은 ready_threads) running이거나 ready state를 가지고 있는 쓰레드의 수이며, 이때 idle thread의 수는 세지 않는다.
Fixed-Point Real Arithmetic (고정 소수점 실수 연산)
위 공식들을 살펴보면, priority, nice, ready_thread 등은 전부 정수이지만, recent_cpu와 load_avg의 경우는 실수이다. 허나 Pintos는 커널에서 부동 소수점 산술을 지원하지 않는다. 부동 소수점 산술은 커널을 복잡하고 느리게 만들기 때문이다. 이는 실제 커널들도 동일한 이유를 들어 같은 제한을 가지고 있는 경우가 많다. 이는 다시 말해, 실제 양에 대한 계산은 정수를 사용하여 모의실험을 해야 함을 나타낸다. 어렵지는 않지만, 많은 학생들이 이 방법을 모르고 있기에, 여기서는 이를 수행하는 방법에 대해 설명한다.
기본적인 방법은 정수의 가장 오른쪽 비트를 분수로 생각하는 것이다.
예시로, 부호가 붙은 32비트 정수를 가정하자. 이의 가장 낮은 14비트를 분수 비트로 지정하여 정수 $x$ 가 실수 $x/(2^(14))$ 를 표현할 수 있다. 소수점 앞에 17비트가 있고, 이후 14가 있고 마지막으로 부호를 나타내는 비트가 있기 때문에 이를 17.14 고정 소수점 표현이라고 한다. 17.14 포맷은 최대로 $(2^(31) -1) / (2^(14)) ≈ 131,071.999$ 를 나타낸다.
우리가 p.q 의 고정 소수점 표현을 사용한다고 가정하고, $f = 2^q$ 라고 가정하자. 위 정의에 따라, 우리는 정수나 실수를 $f$ 를 곱함으로써 p.q 포맷으로 교환할 수 있다.
예시로, 17.14 포맷에서 우리가 load_avg를 위에서 계산할 때 사용하던 분수인 $59/60$ 을 표현한다고 하자. 이것은 $(59/60) * 2^(14) = 16,110$ 으로 표현할 수 있다. 고정 소수점으로 표현한 것을 다시 정수로 표현하기 위해서는 $f$ 로 나누면 된다.(일반적으로 / 연산자는 C에서 0을 향해서 정수로 바꾸는 작업을 한다. 양수는 낮추고, 음수는 올린다. 근처로 옮기기 위해서는 $f/2$ 를 양수에 더하고, 음수에 빼는 과정을 나누기 전에 수행하면 된다.)
많은 고정 소수점 숫자는 간단하다. x, y를 고정 소수점 숫자라고 하고, n을 정수라고 하자. 그러면 $x + y$ 가 이들의 합, $x - y$ 가 이들의 차이다. $x + n$ 은 $x + n * f$, $x - n$ 은 $x - n * f$ , 곱은 $x * n$ , 몫은 $x / n$ 이다.
두 고정 소수점 숫자의 곱은 조금 어렵다. 먼저, 결과의 소수점은 q 비트만큼 너무 멀리 좌측에 있다. $(59/60) * (59/60)$ 은 1보다 약간 작아야 하지만, $16,111 * 16,111 = 259,564,321$ 은 $2^(14) = 16,384$ 보다 훨씬 크다. q비트를 오른쪽으로 이동하면 $259,564,321 / 2^(14) = 15,842$, 즉 정답은 0.97이 된다. 또한, 답이 표현 가능하다고 하더라도 곱셈이 넘칠 수 있다. 예시로 17,14 형식의 64는 $64 * 2^(14) = 1,048,576$ 이고, 제곱 $64^2 == 4,096$ 은 17.14 범위 내에 있지만, $1,048,576^2 = 2^40$ 은 부호가 있는 최대 32비트 정수의 값인 $2^(31) -1$ 보다 크다. 쉬운 해결책은 곱셈을 64비트 연산으로 하는 것이다. 이에 따라, $x * y$ 는 ((int64_t) x) * y / f 가 된다.
두 고정 소수점 숫자의 나눗셈은 반대의 문제점을 가지고 있다. 결과의 소수점은 너무 멀리 우측에 있을 것이며, 우리는 이를 나눗셈을 진행하기 전에 dividend 를 q bits 만큼 좌측으로 옮김으로서 해결할 것이다. 좌측으로 이를 옮기는 과정은 위의 q bits를 무시하고 진행될 것이며, 이는 다시 64bits로 나눗셈을 진행할 때 고칠 수 있다. 그러므로, x가 y로 나뉘어질 때, 수식은 ((int64_t) x) * f / y 가 될 것이다.
우리는 지금까지 두가지 이유로 q bit shift 대신 f를 사용한 곱셈이나 나눗셈을 일관적으로 사용하였다. 먼저, 곱셈과 나눗셈은 C에 있는 shift operation 에 대해 특별히 높은 우선순위를 가지고 있지 않으며, 또한 곱셈과 나눗셈은 음수의 피연산자에 대해 잘 정의되어 있으나, C에 있는 shift operation은 그렇지 않다. 구현할 때, 이러한 부분에 주의를 기울여야 할 것이다.
다음 표는 C에서 고정 소수점 연산을 구현할 수 있는 방법을 요약한 것이다. 표에서 x와 y는 고정 소수점 숫자이고, n은 정수이며, 고정 소수점 숫자는 부호가 있는 p.q 형식이고, 여기서 p + q = 31, f는 1«q 가 될 것이다.
| Arithmetic | C |
|---|---|
| Convert n to fixed point | n * f |
| Convert x to integer (rounding toward zero) | x / f |
| Convert x to integer (rounding to nearest) | (x + f / 2) / f if x >= 0 |
(x - f / 2) / f if x <= 0 |
|
| Add x and y | x + y |
| Subtract y from x | x - y |
| Add x and n | x + n * f |
| Subtract n from x | x - n * f |
| Multiply x by y | ((int64_t) x) * y / f |
| Multiply x by n | x * n |
| Divide x by y | ((int64_t) x) * f / y |
| Divide x by n | x / n |
PinotOS 강의 - 권영진 교수님
서론
운영체제를 이해하는 방법
bottom-up이 아닌 top-down 방식을 사용하라! 기능을 구현하는 것에 집중하는 것이 아니고, 각 기능이 왜 필요한지를 이해하고, 이를 기반으로 내려가면서 만들어야 한다.
1장 무엇이 일어나고 있는가!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#include <stdio.h>
#include <string.h>
#include <sys/mman.h>
#include <sys/time.h>
int main(void)
{
void *addr;
struct timeval start, end, elap;
addr = mmap(NULL, 1 << 20, PROT_READ | PROT_WRITE, MAP_ANONYMOUT | MAP_PRIVATE, -1, 0);
gettimeofday(&start, NULL);
memset(addr, 1, 1<<20);
gettimeofday(&end, NULL);
timersub(&end, &start, &elap);
printf("Time taken to memset1 %ld usec\n", elap.tv_usec);
gettimeofday(&start, NULL);
memset(addr, 2, 1<<20);
gettimeofday(&end, NULL);
timersub(&end, &start, &elap);
printf("Time taken to memset2 %ld usec\n", elap.tv_usec);
munmap(addr, 1 << 20);
}
위에서 mmap은 2MB(1 « 20)의 공간을 할당한다.
같은 작업에서 둘의 시간 차이가 나는 이유는 캐시 때문이다.
이를 다음과 같이 수정해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#include <stdio.h>
#include <string.h>
#include <sys/mman.h>
#include <sys/time.h>
#define MAP_SIZE (1<<30)
int main(void)
{
void *addr;
struct timeval start, end, elap;
addr = mmap(NULL, MAP_SIZE, PROT_READ | PROT_WRITE, MAP_ANONYMOUT | MAP_PRIVATE, -1, 0);
gettimeofday(&start, NULL);
memset(addr, 1, MAP_SIZE);
gettimeofday(&end, NULL);
timersub(&end, &start, &elap);
printf("Time taken to memset1 %ld usec\n", elap.tv_usec);
gettimeofday(&start, NULL);
memset(addr, 2, MAP_SIZE);
gettimeofday(&end, NULL);
timersub(&end, &start, &elap);
printf("Time taken to memset2 %ld usec\n", elap.tv_usec);
munmap(addr, 1 << 20);
}
이런식으로 수정하게 되면 기존 10배의 차이가 나던 것이 2배의 차이로 감소한다. 그 이유는 무엇일까?
이제 캐시의 영향은 감소하였다(location size가 1GB(1«30)이 되었기 때문). 그렇다면 지금의 차이가 나는 이유는 무엇일까?
디맨드 페이징.
운영체제가 실제로 page fault가 나서, page demanding을 하는 과정이 포함이 된다. 두번째에는 이것이 발생하지 않는다.(이미 가상 메모리에 올린 것이 나오기 때문)
추상화
운영체제의 가장 중요한 requirements는 바로 추상화이다. 모든 interface는 추상화를 통해 만들어져있고, 메모리의 관리 등의 관점에서 이에 대한 결과물을 봐야하기 때문.
Problem size가 증가할수록 Complxity는 기하급수적으로 증가한다.
운영체제도 마찬가지.
그래서 이를 Divide and conquer를 해야한다.
이를 분할해서 하나씩 추상화하면, 이는 계속 Layer가 쌓여가고, 이것이 Layer of Abstraction이 된다.
운영체제에서는 결국 Resources 별로 쪼갠다!
인터페이스를 통해 이 리소스에 접근하게 만든다!
John Ousterhout - A Philosophy of Software Design
fundamental act가 소프트웨어 디자인에 없다는 것… 이건 너무 큰 문제라는 것이 영상의 중점이다.
딱 하나의 아이디어/컨셉트만 골라야 한다면? -> Abstraction. (Composition)(Complxity)?
또 유명한 교수은 Layers of Abstraction.
정의에 따르면 맞지만, 영상에서는 problem decomposition이라고 했다.
추상화라는 것이 결국 제일 중심적인 것이다.
왜 OS가 필요한가?
기존 OS가 없었을 때에는 모든 기기를 사용자가 직접 관리해야 하지만, 이 사이의 API(Application Programming Interface)를 만들어, 다양한 하드웨어들을 마주할 수 있도록 만든 것.
그렇기에, 디바이스에 따라 분할하여 추상화해야 한다.
Abstraction / Protection & Isolation / Sharing
Abstraction 이란 무엇인가?
디테일을 무시하여 쉽게 이해할 수 있도록 만든 것.
Abstract(정글)을 만든다고 생각해보자. 이는 정글을 인지 하고 이를 정의 하는 과정이 들어간다.
여기에 불필요한 디테일은 전부 ignore 한다.
즉, 반드시 필요한 디테일만 가지고 추상화를 진행한다.
OS designers’ first thought
하드웨어의 디테일을 신경쓰면서 프로그램을 만들고 싶지 않다. 즉, 쉽게 프로그래밍 할 수 있어야 한다.
OS는 Application을 다뤄야 한다, (hardware resources를 utilize 해야 한다)(management unit of execution)
Protect applications from each other(protection unit of execution)
===> PROCESS
Building an abstraction…
how to make it easy to use hardware?

마지막줄 OS designers provide APIs to application to use the abstraction -> They call them as system calls
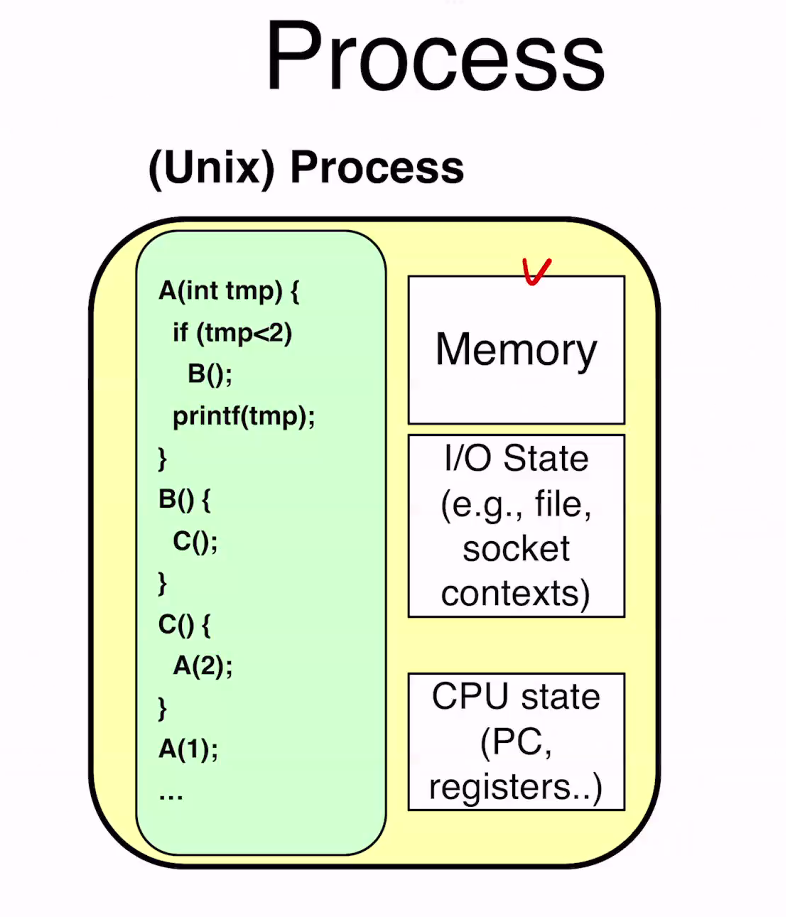
이중 우측 Memory와 I/O State는 Resources.. 좌측은 Sequential 한 명령들..
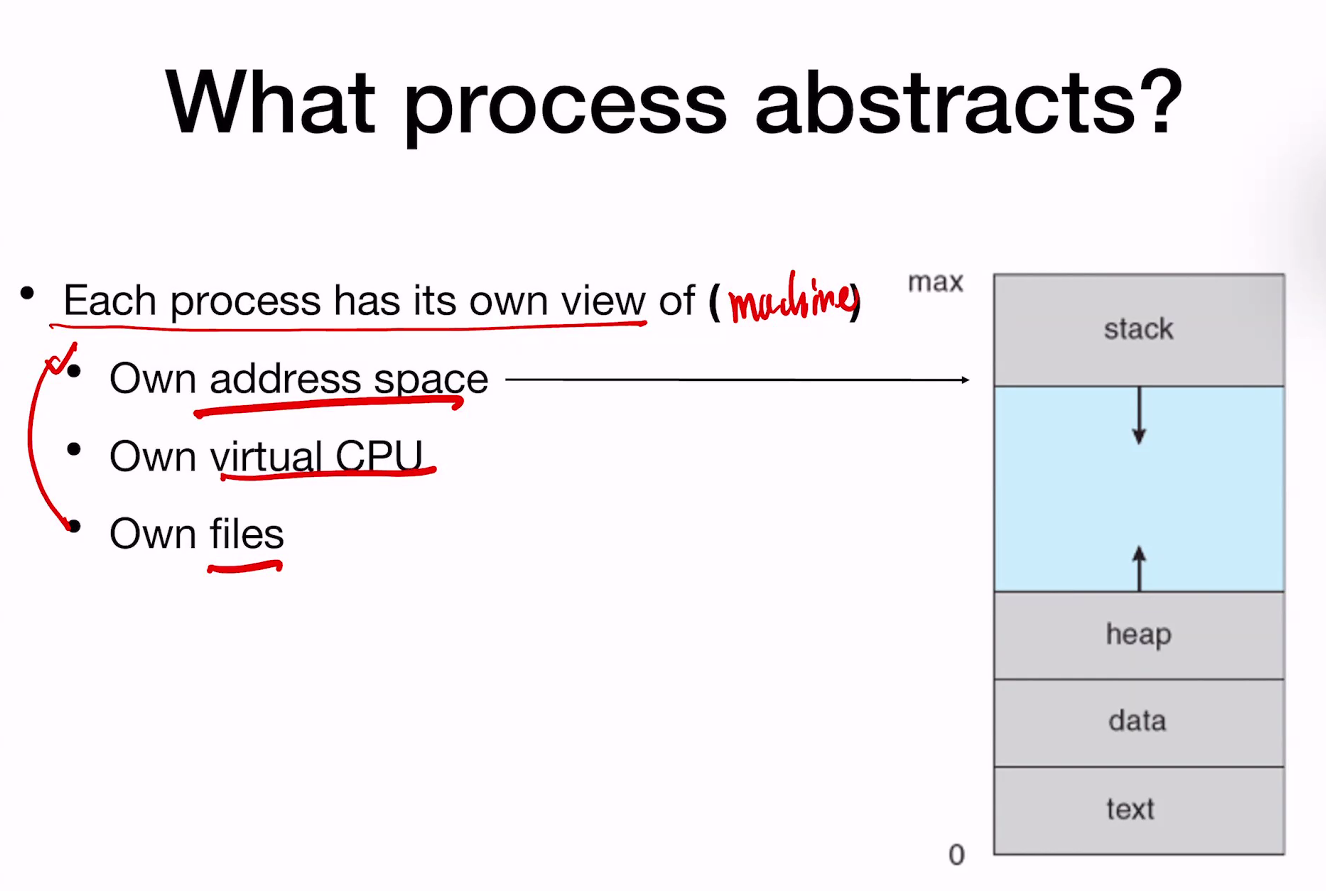
일반적으로 프로세스의 가상 메모리 역시 stack/heap/data/text의 영역으로 나뉜다. 로더는 나의 binary를 읽어서 이런 식으로 올려준다. 이것은 lab 2 에서 진행하게 될 것이다…
이제 각 추상화된 공간들을 따로 추상화해야…?
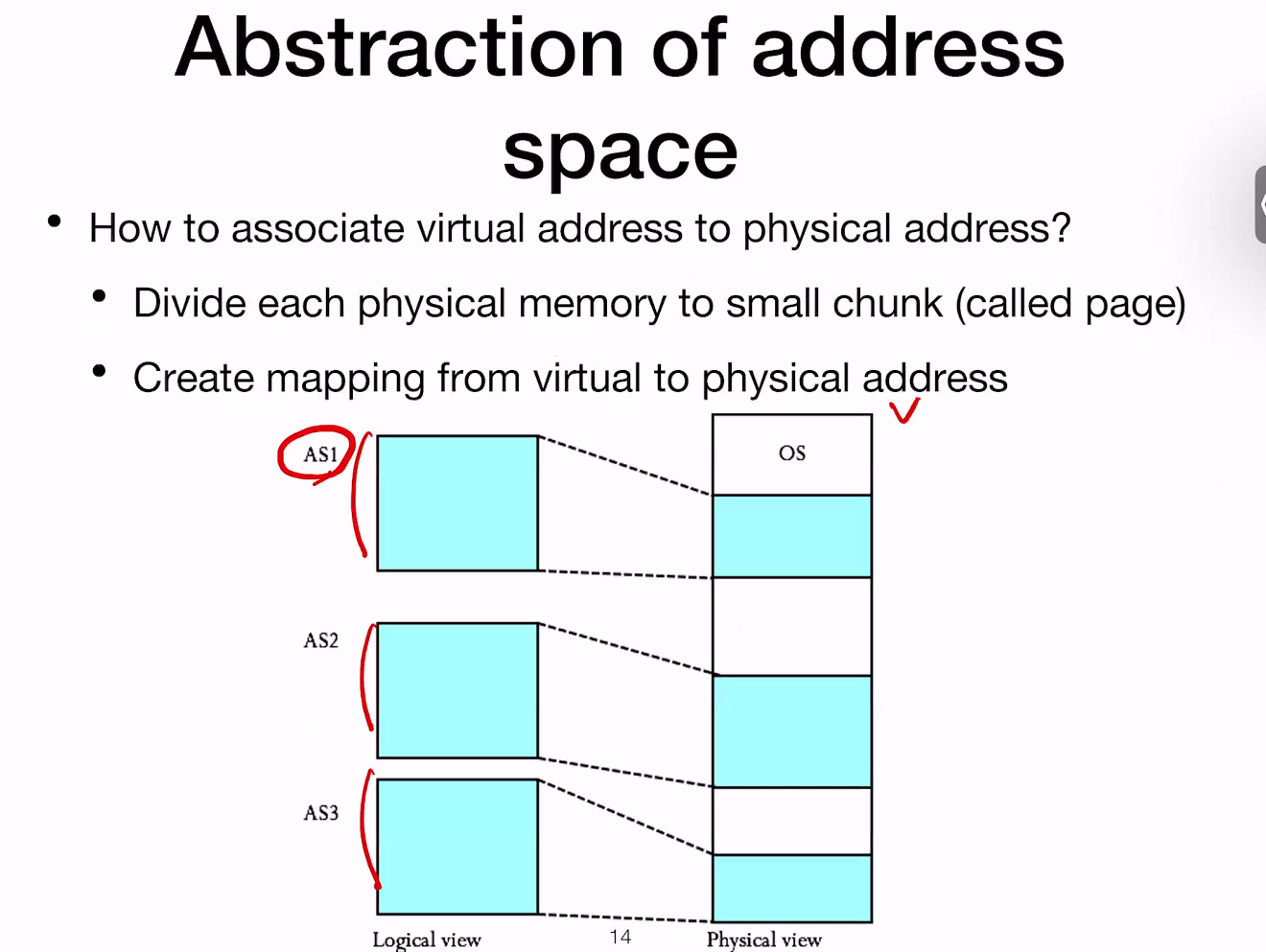
4KB바이트의 페이지를 통해 Logical 및 physical 사이의 mapping을 진행한다.
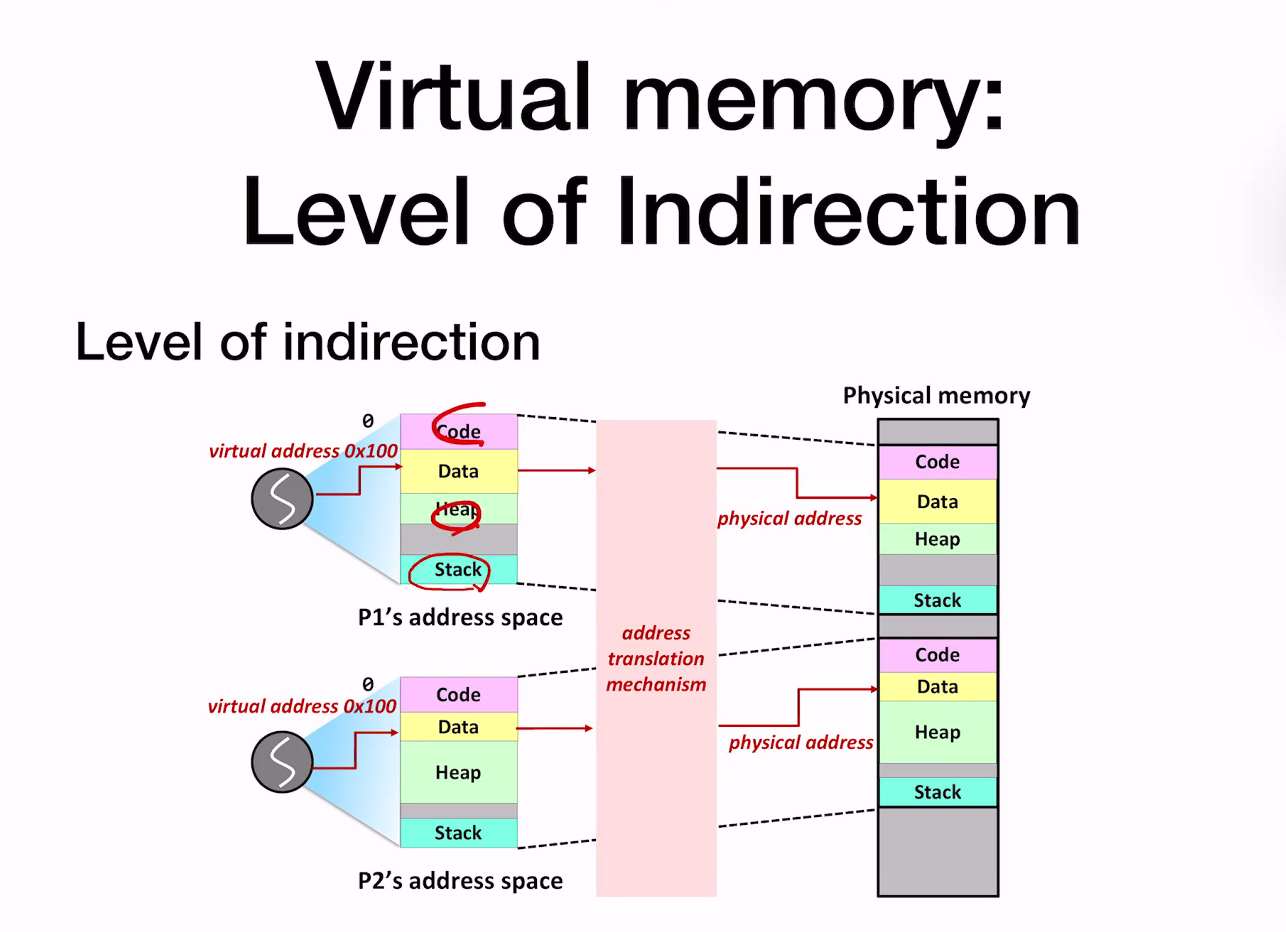
Level of indirection :
address란 어떠한 값을 가지고 address translation mechanism을 통해 변환… 가상 주소 공간에서 func의 input은 virtual address. 이를 가지고 physical address를 반환해준다.
즉 address translation mechanism을 가지고 변환을 진행하는데,
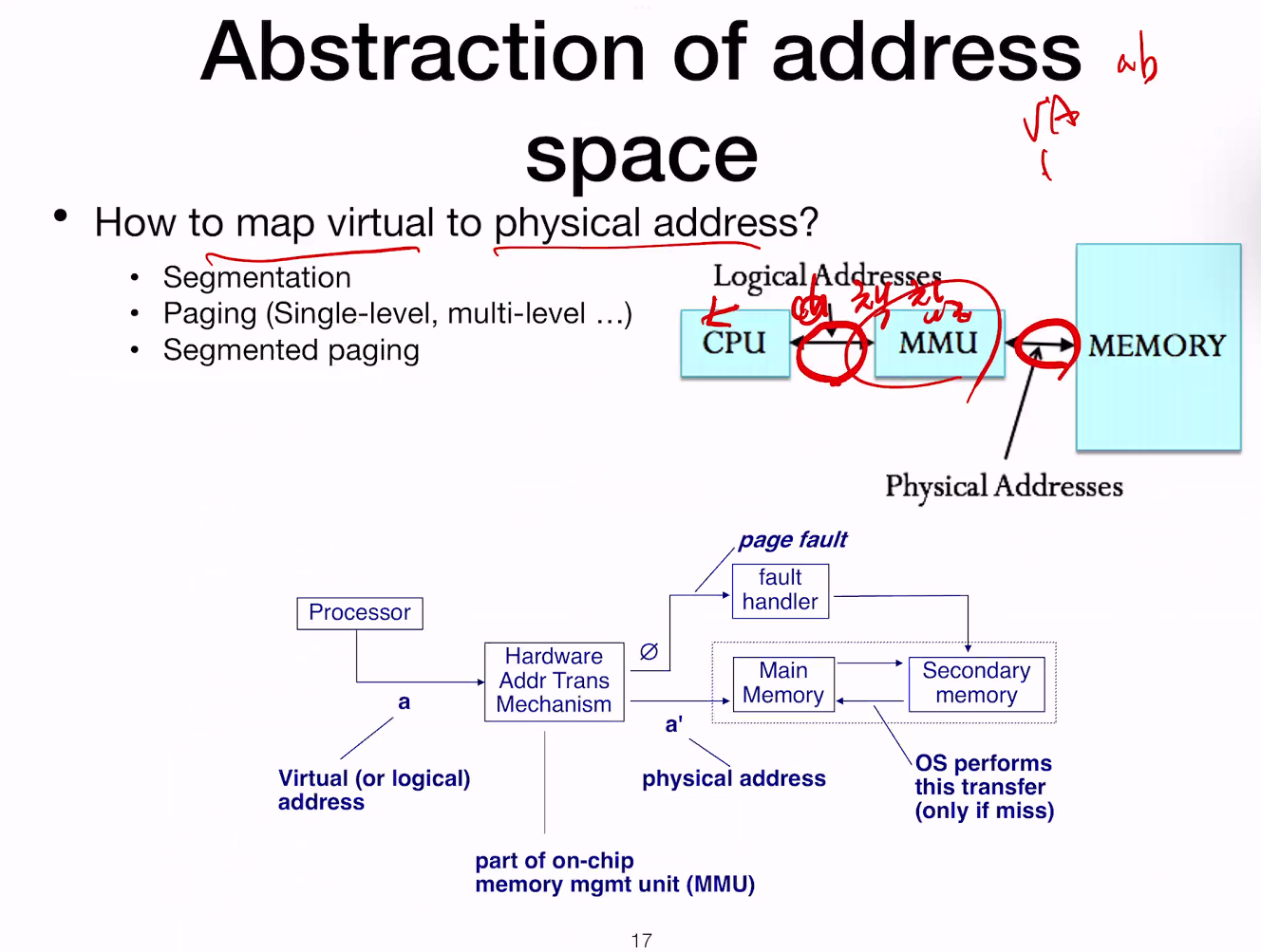
하드웨어와 커널은 서로 소통을 한다.
이때, 왜 memory 관련 부분만 하드웨어 부분에 구현이 되어 있을까??
DRAM이 매우 빠르기 때문. 이를 소프트웨어로 구현하면, 이는 느리기 때문에 성능저하가 발생. 그래서 하드웨어에서 제작한다.
잠시 추가…
Page table은 어디에 저장되어 있는가? 페이징을 할 때 OS의 역할은 무엇인가? 페이징을 할 때 하드웨어의 역할은 무엇인가?
계속…
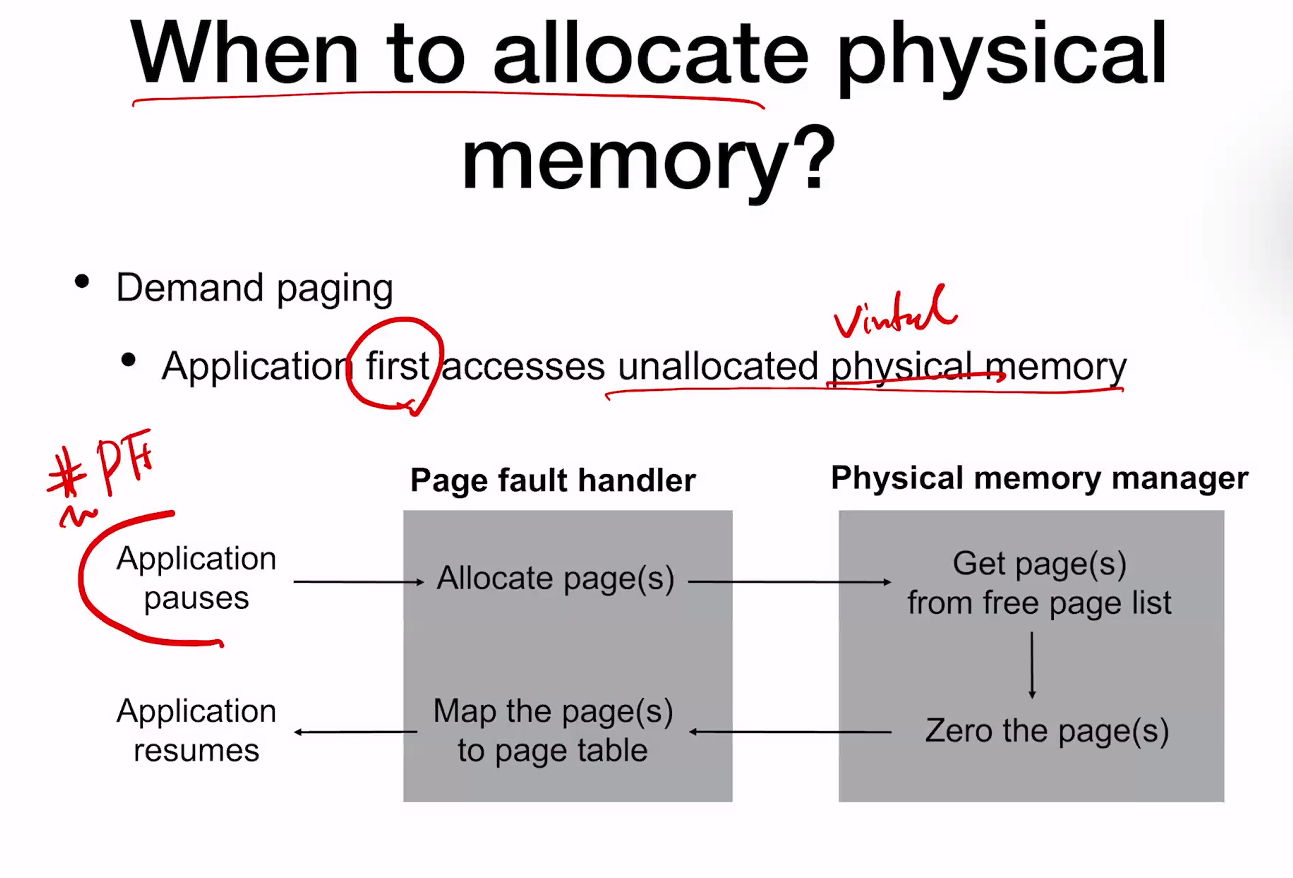
언제 physical memory를 allocate(찾을)것인가?
Demand Paging : Application first accesses unallocated virtual(ppt 오타) memory. -> 필요할 때 가져온다~
Page fault가 발생하면 그때 가져오는 것.
이때, Zero the page의 부분이 가장 오래 걸린다. 하지만, 이 부분은 지울 수 있을것 같다고 생각했지만, 0으로 만드는 과정이 반드시 필요하다. Protection이 중요하기 때문이다.
하지만 malloc에서 0이 안되는 이유는, 같은 process에서 malloc으로 전달해 주는 것이기 때문이다. 이는 demand paging과는 또 다르다. 조금 더 찾아보자.
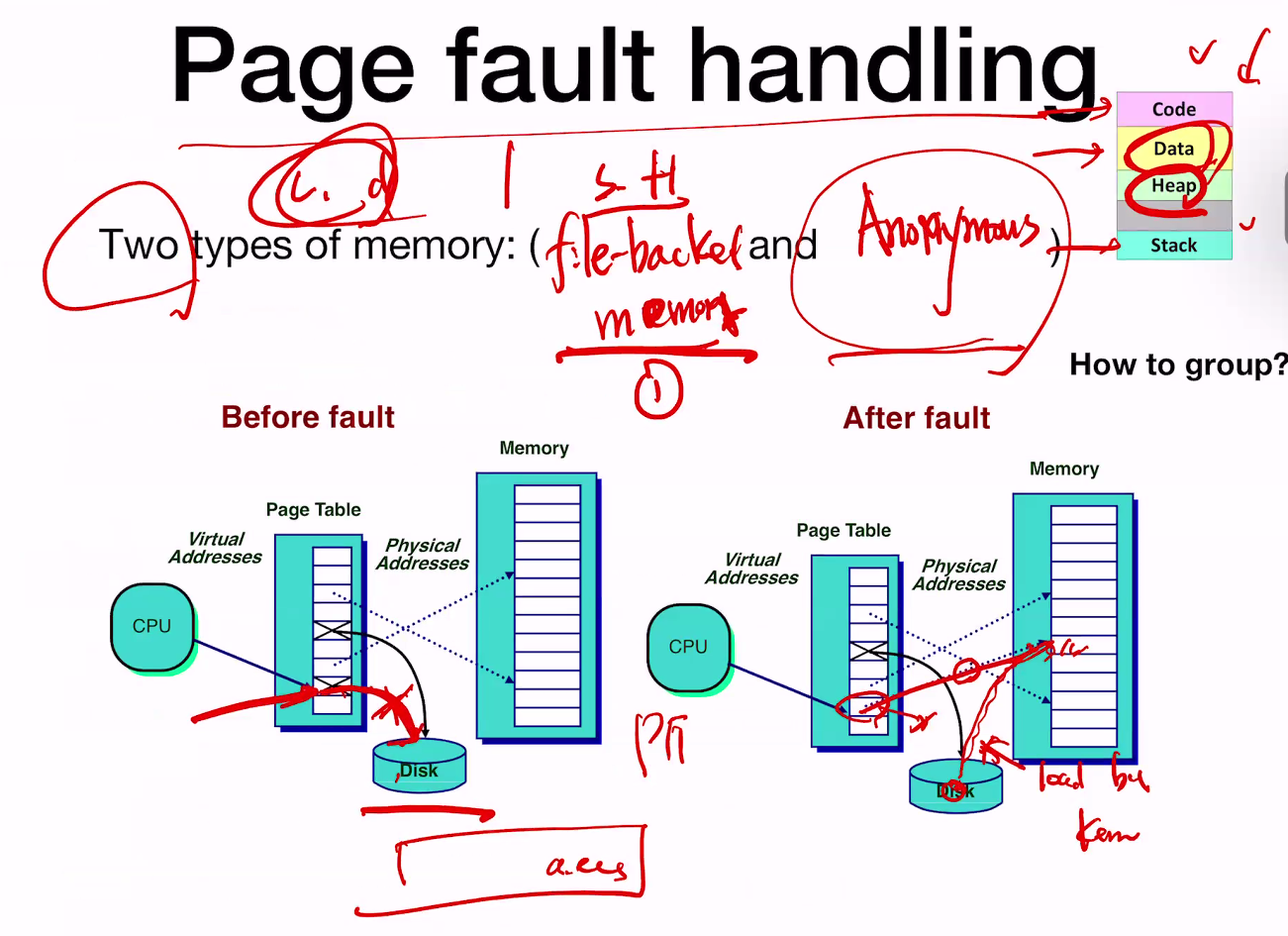
Page fault handling
두개의 타입의 메모리가 있다.
Two types of memory : (file-backed memory and Anonymous Memory)
file-backed는 page fault 시에 disk에서 읽어오는 메모리. 코드, 데이터 등.
Anonymous memory는 page fault시에 zero the page하는 메모리…? 스택과 힙이 속한다. 이것도 조금 더 찾아보자.
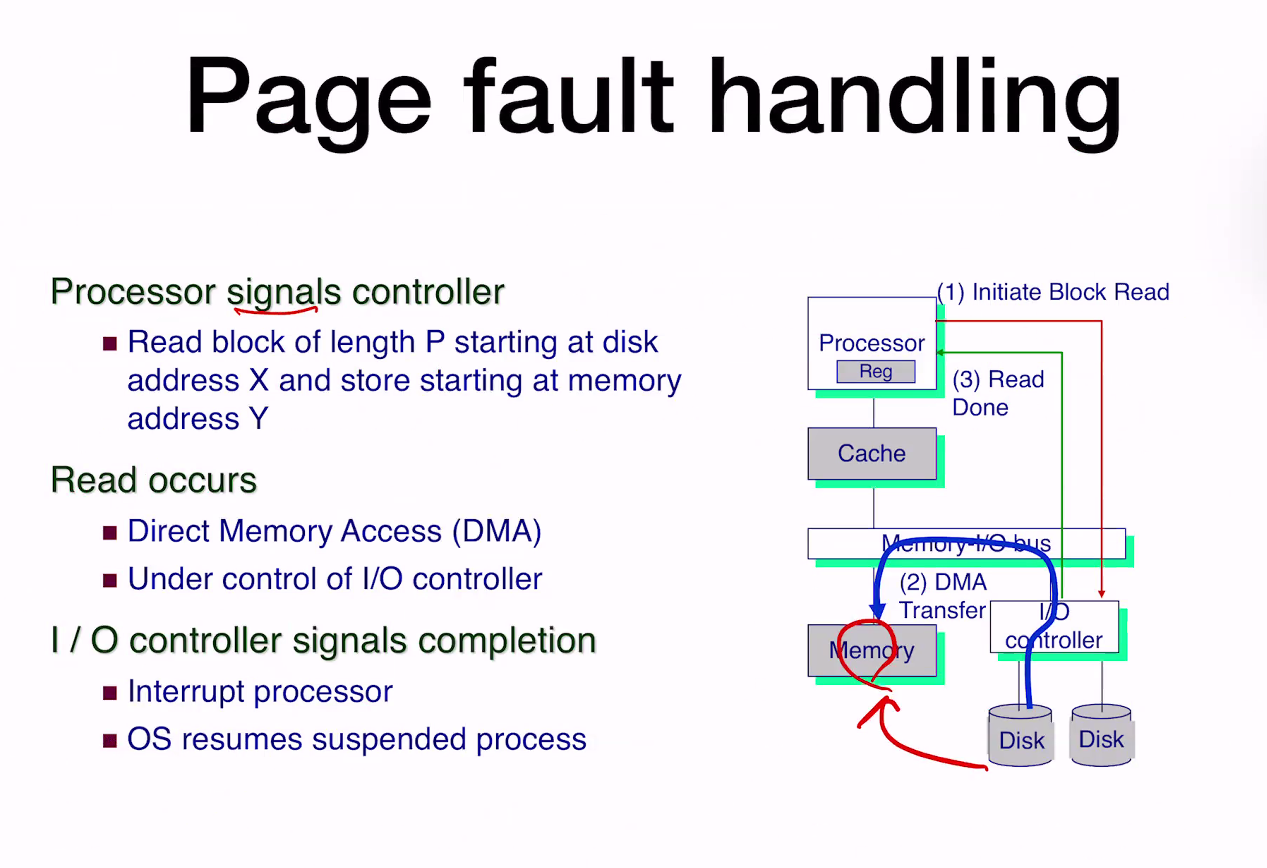
DMA - CPU를 bypass해서 직접 메모리에 접근하는 것. (3) Read Done에 Device가 CPU에게 날려주는 Signal -> Inturrupt라고 한다.
Abstraction of storage(저장 추상화)
- File: a logical unit of storage
- Identifier : pathname(path + filename)
- Location of data is identified by (offset)
- Analogy
- Virtual memory is an abstraction of physical memory
- Level of indirection: (VA) -> (PA)
- File is an abstraction of physical storage
- Level of indirection: (filename, offset) -> (block address)
- Virtual memory is an abstraction of physical memory
File System: A Mapping Problem
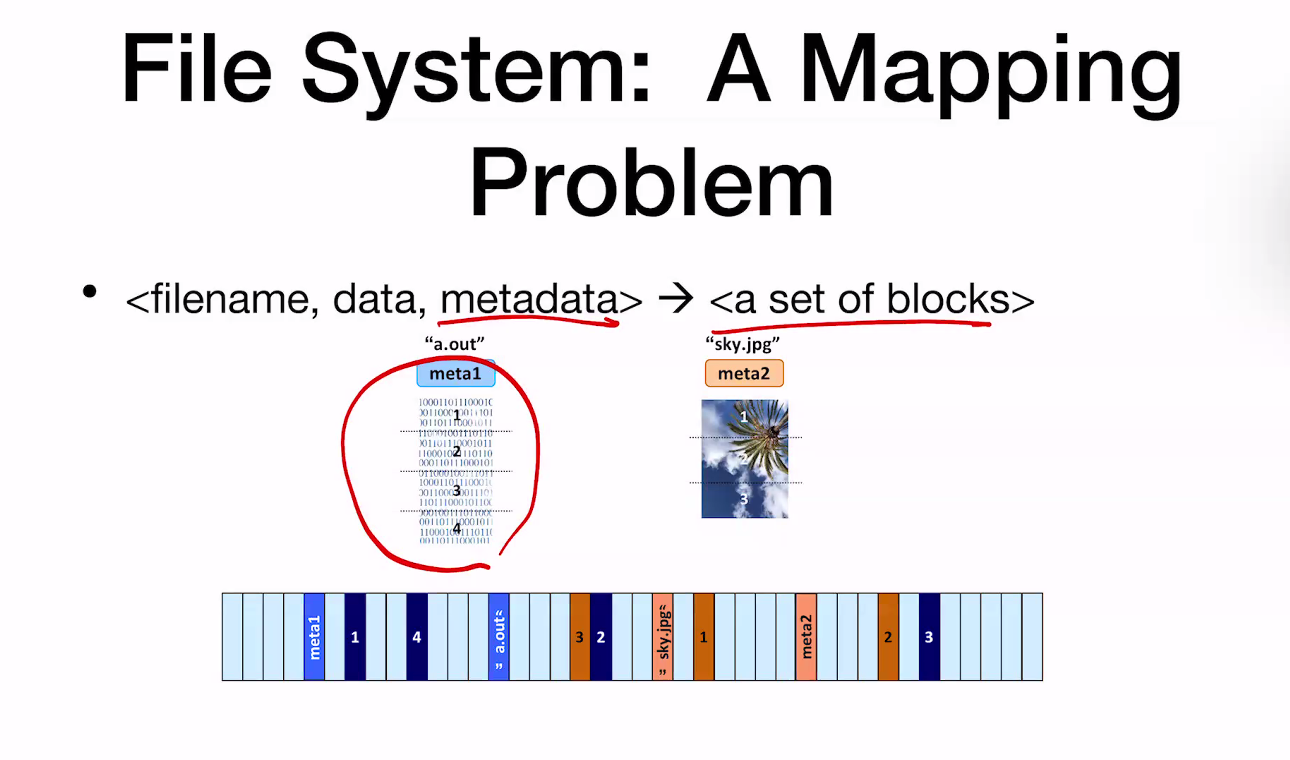
- filename, data, metadata -> a set of blocks
Abstraction of stage
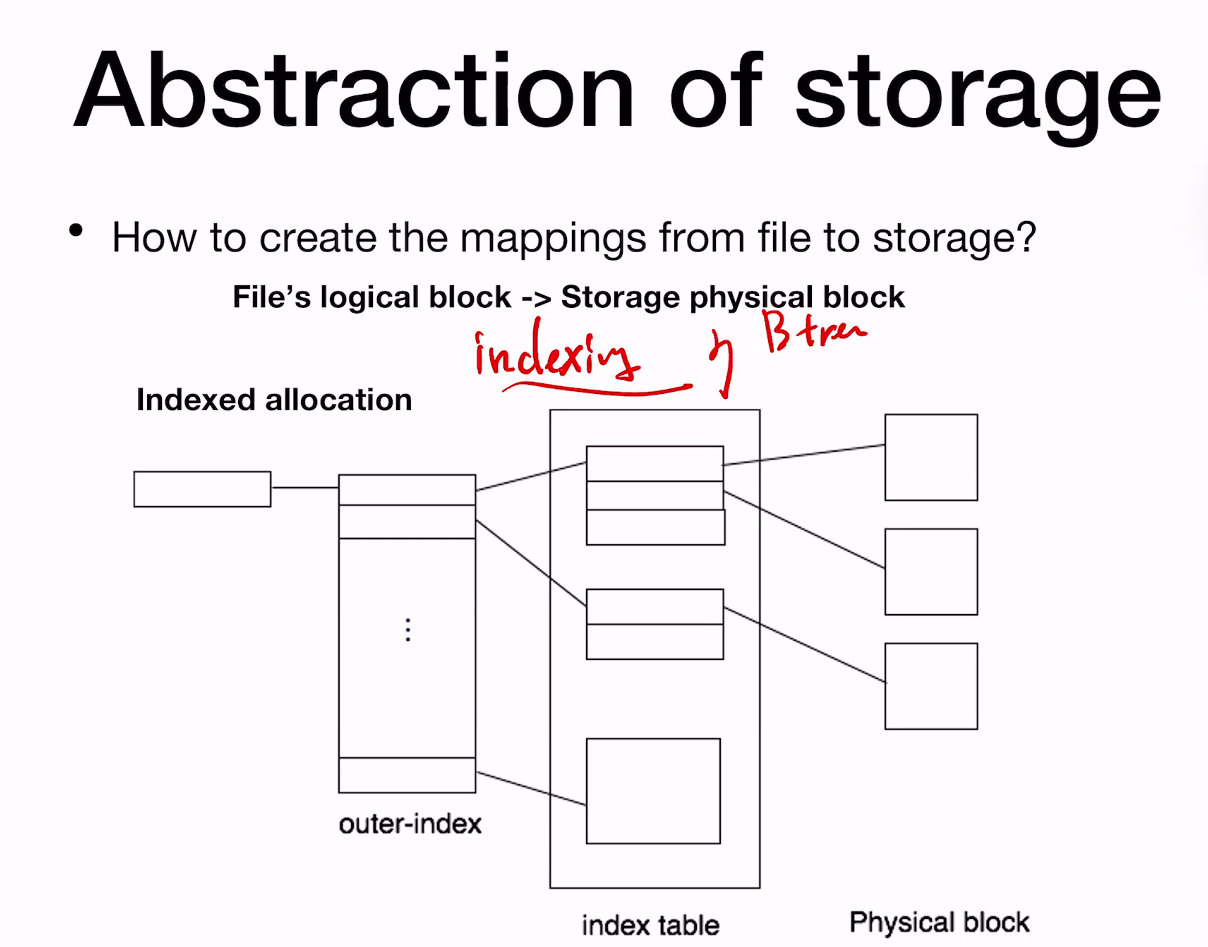
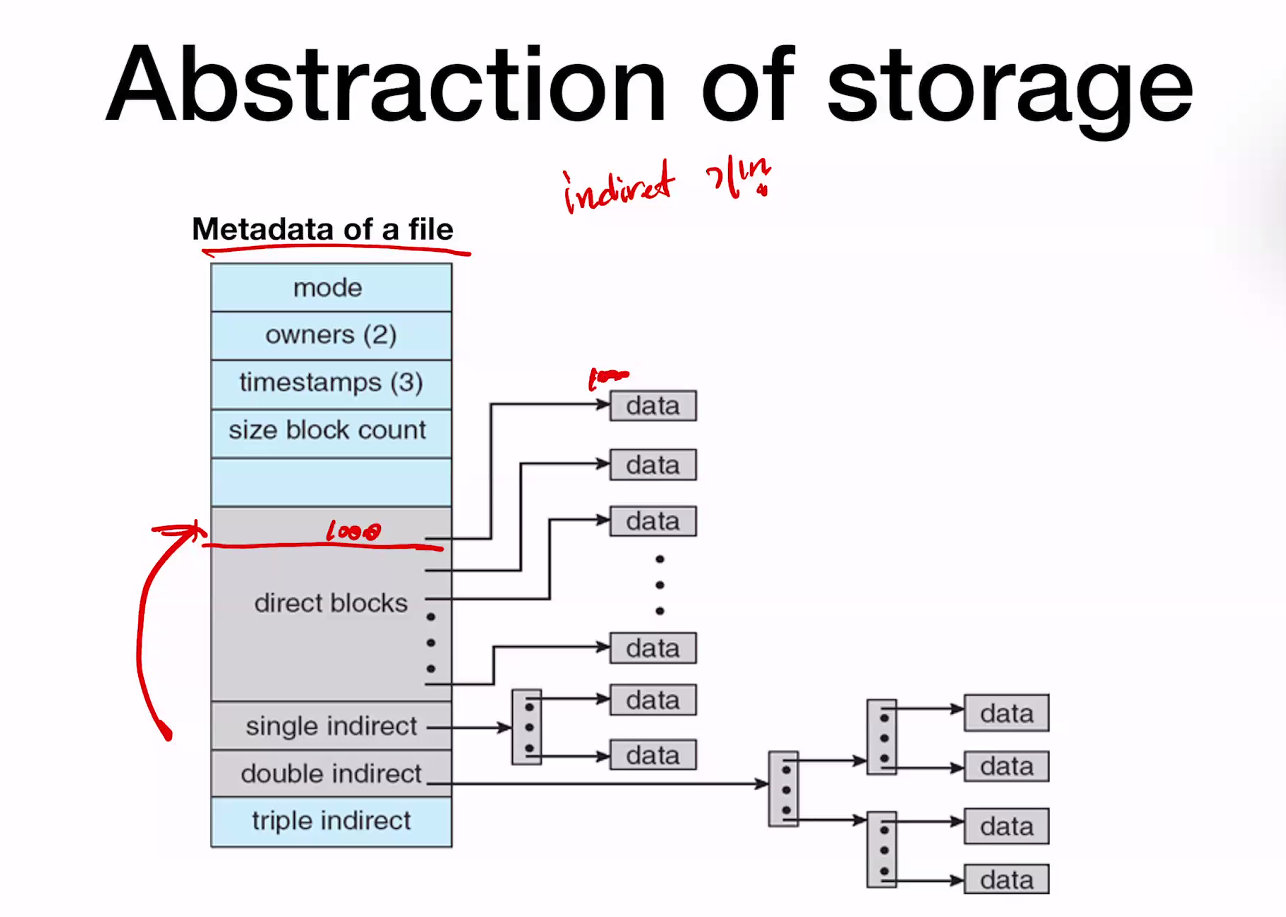

internodes는 storage에 저장.
hardware는 indexing을 돕지 않는다.
allocate physical block? 저장시 -> fsync
Any performance optimization for slow storage device? -> Storage stack overview를 보시오.
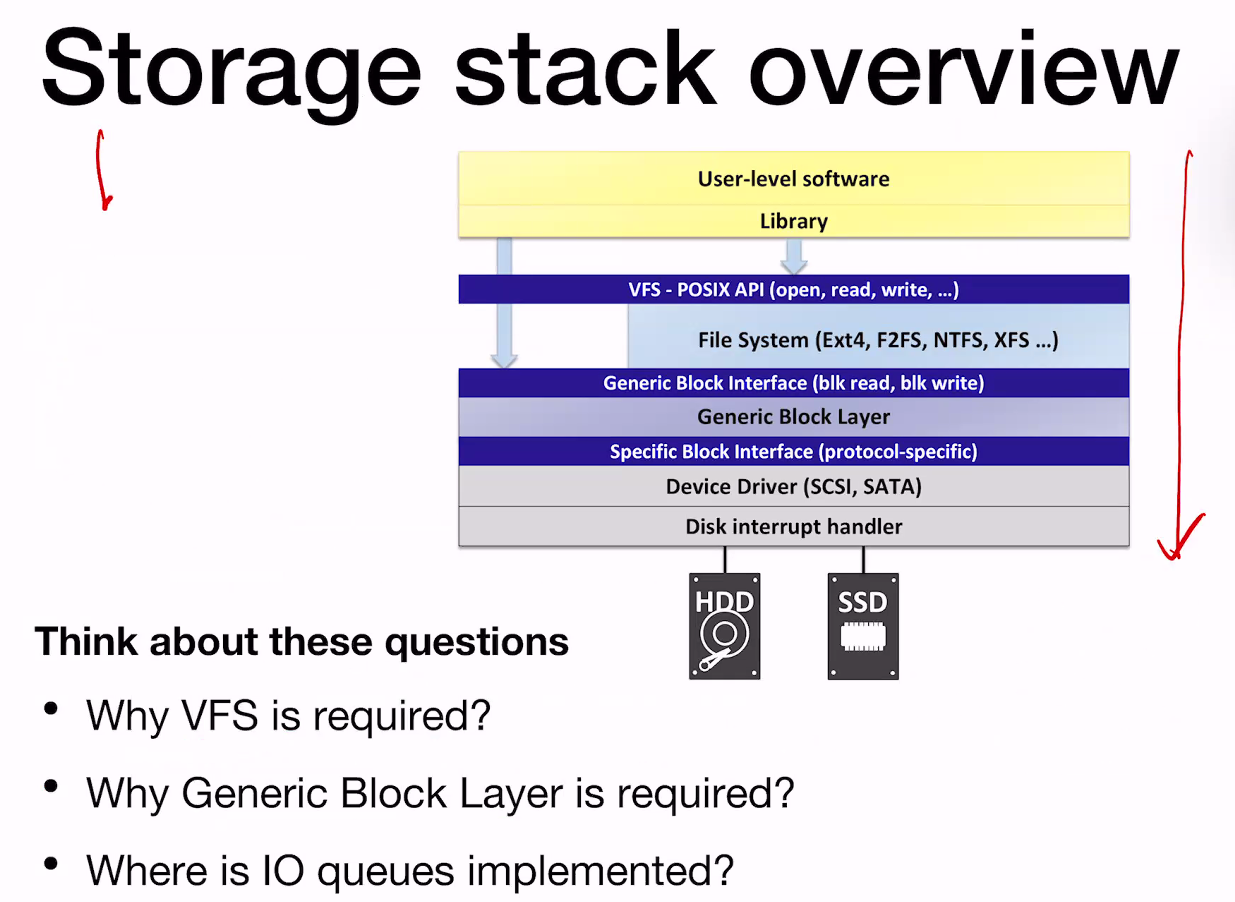
이것이 Layer of abstraction.
Any performance optimization for slow storage device?
데이터를 먼저 DRAM에 올린다고 하자. DRAM Location 의 이름을 Page cache라고 한다. Page cache는 어디에 구현될까?
기존에는 Generic Block Interface부터 Specific Block interface 사이에 구현되었으나, 이를 올려서 현재는 VFS-POSIX API에 구현이 되어있다.
I/O Queue는 어디에 구현되어 있을까? Generic Block Interface부터 Specific Block interface 사이에 구현되어 있다.